
How to Write Speech Recognition Applications in C#
In this article, we will discuss how to use Microsoft’s Speech Recognition Engine to write a virtual assistant application. Speech recognition apps are the way of the future and they are actually easy to write using Microsoft.Speech Recognition.
Speech Recognition Operations
A speech recognition application will typically perform the following basic operations:
- Start the speech recognizer.
- Create a recognition grammar.
- Load the grammar into the speech recognizer.
- Register for speech recognition event notification.
- Create a handler for the speech recognition event.
Free Speech Recognition API
If you are looking for a free solution for a hobby application or if you’re just trying to get your MVP built for your application, this is a nice place to start. You could swap over the code later to use for more expensive APIs available.
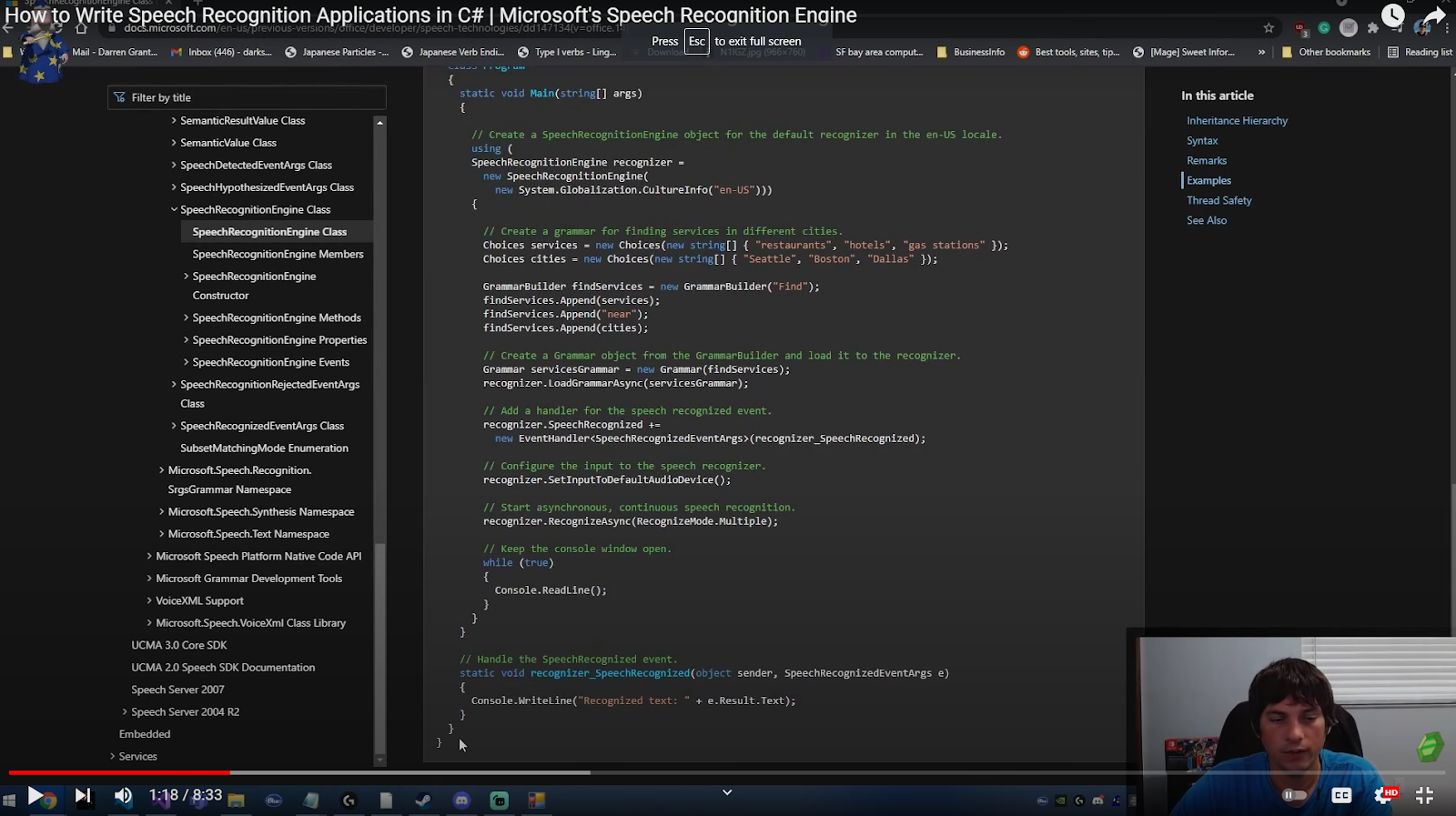
In this video, I also referenced Microsoft documentation, you could access this through this link. We used this example, they also have a console app built here.
The first step is to add the following line.
microsoft.speech.recognitionYou need to import the speech recognition engine first and to do that, adding the reference is a must. Navigate to your Solution Explorer and find “References” and search for speech.
You need to add a reference to the System.Speech assembly, which is located in the GAC.
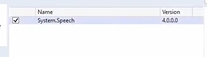
This is the only reference needed. It contains all of the following namespaces and classes. The System.Speech.Recognition namespace contains the Windows Desktop Speech technology types for implementing speech recognition.
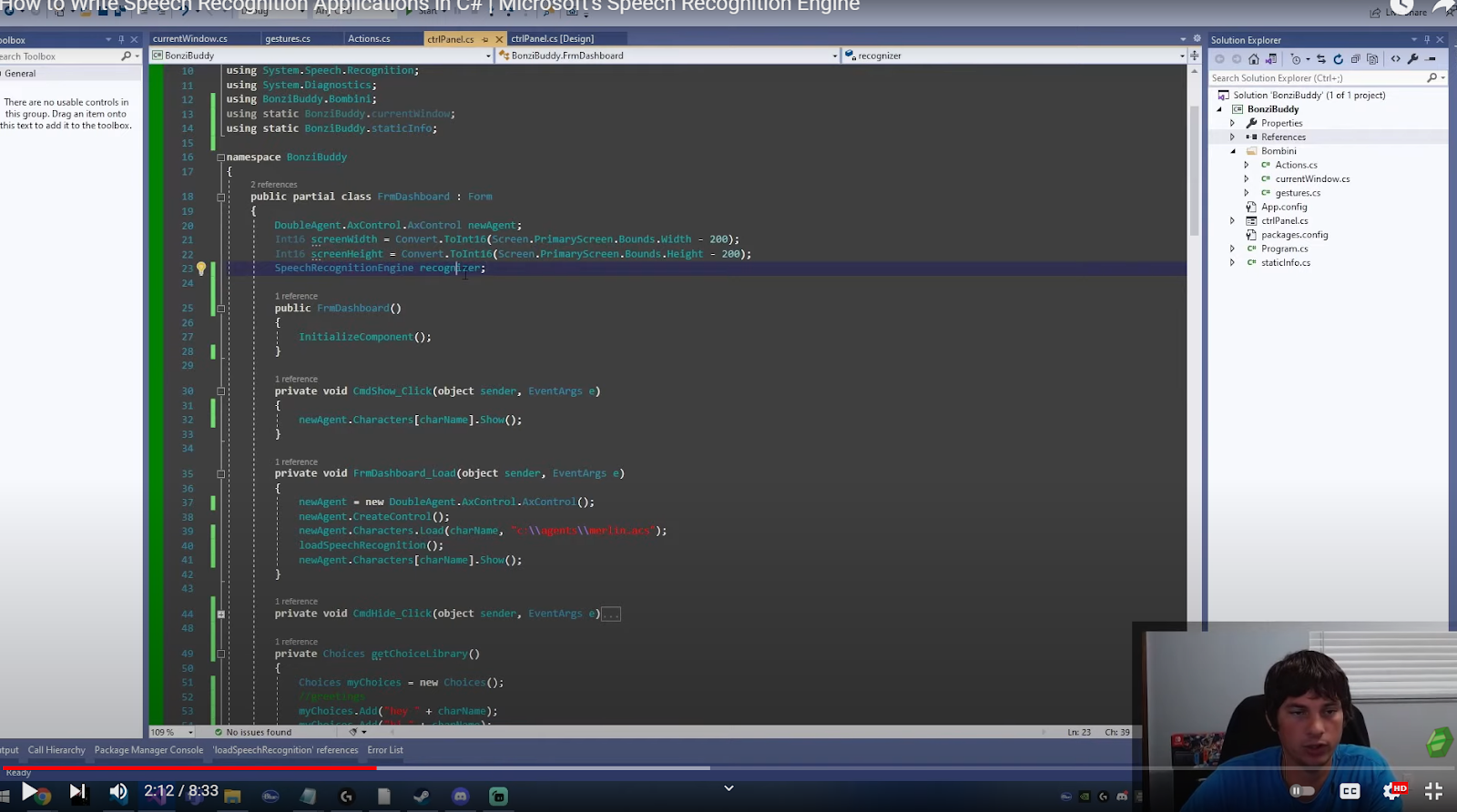
Before you can use the Microsoft SpeechRecognitionEngine, you have to set up several properties and invoke some methods. The next step now is to create a new recognizer. In the video, at the top of my class, I’ve created an empty object for the recognizer.
// Create an in-process speech recognizer for the en-US locale.
recognizer = new SpeechRecognitionEngine(new System.Globalization.CultureInfo("en-US"));
On load, I have the following code.
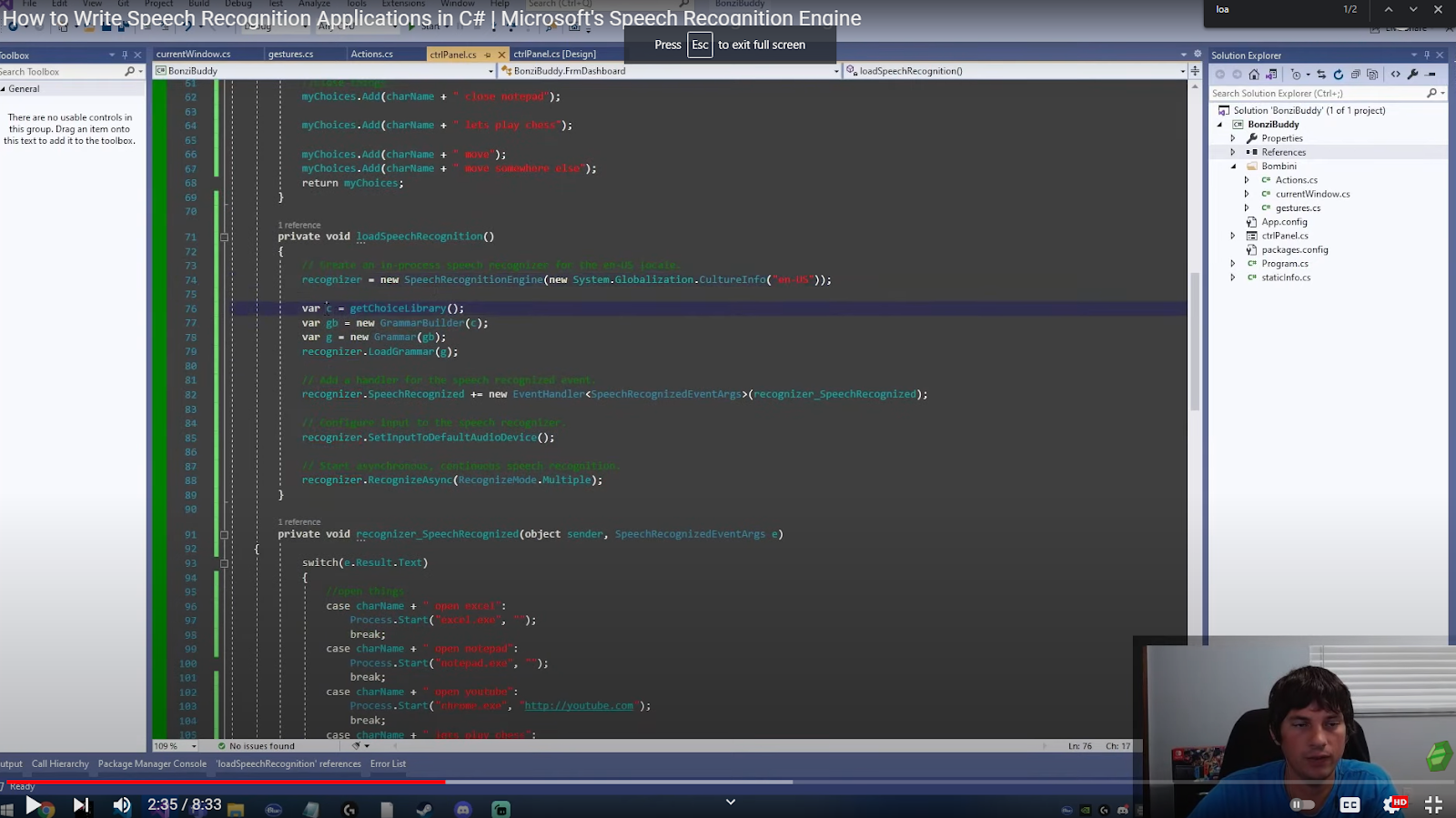
loadSpeechRecognition(); This is a function that has the loading code for the recognizer. We create a new speech recognition engine and pass it as a language because this works in multiple languages.
private void loadSpeechRecognition()
{
// Create an in-process speech recognizer for the en-US locale.
recognizer = new SpeechRecognitionEngine(new System.Globalization.CultureInfo("en-US"));
var gb = new GrammarBuilder(getChoiceLibrary());
var g = new Grammar(gb);
recognizer.LoadGrammar(g);
// Add a handler for the speech recognized event.
recognizer.SpeechRecognized += new EventHandler<SpeechRecognizedEventArgs>(recognizer_SpeechRecognized);
// Configure input to the speech recognizer.
recognizer.SetInputToDefaultAudioDevice();
// Start asynchronous, continuous speech recognition.
recognizer.RecognizeAsync(RecognizeMode.Multiple);
}
Instantiate your recognizer and then you are going to build this choice library.
If you look back to the SpeechRecognitionEngine Class that is linked in this article, they created a list of choices. In your application, you may create a function that returns a list of choices.
public Choices getChoiceLibrary()
{
Choices myChoices = new Choices();
//greetings
myChoices.Add("hey " + Agent.charName);
myChoices.Add("hi " + Agent.charName);
myChoices.Add("hello " + Agent.charName);
myChoices.Add("bye " + Agent.charName);
myChoices.Add("thanks " + Agent.charName);
//open things
myChoices.Add(Agent.charName + " open notepad");
myChoices.Add(Agent.charName + " open youtube");
myChoices.Add(Agent.charName + " open excel");
myChoices.Add(Agent.charName + " open discord");
myChoices.Add(Agent.charName + " open davinci");
myChoices.Add(Agent.charName + " play some music");
//Rocket
myChoices.Add(Agent.charName + " say nice shot");
myChoices.Add(Agent.charName + " say sorry");
myChoices.Add(Agent.charName + " say no problem");
myChoices.Add(Agent.charName + " say thanks");
myChoices.Add(Agent.charName + " say great pass");
myChoices.Add(Agent.charName + " say good game");
//Chrome
myChoices.Add(Agent.charName + " close this tab");
myChoices.Add(Agent.charName + " refresh this tab");
myChoices.Add(Agent.charName + " open gmail");
//close things
myChoices.Add(Agent.charName + " close notepad");
myChoices.Add(Agent.charName + " lets play chess");
myChoices.Add(Agent.charName + " open chess");
myChoices.Add(Agent.charName + " move");
myChoices.Add(Agent.charName + " move somewhere else");
return myChoices;
}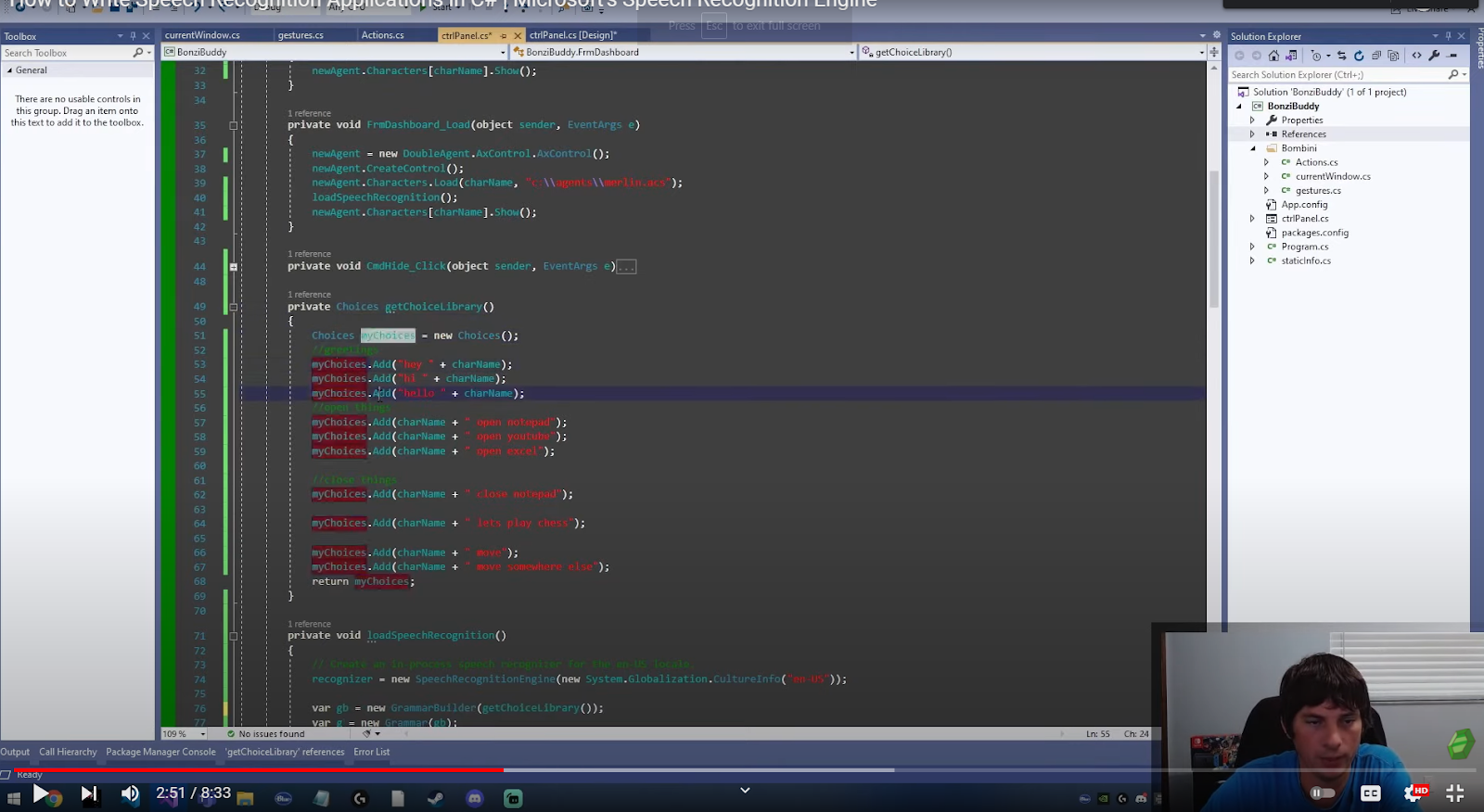
This code creates a new “choices” object and then adds your choices to it.
These pertain to the words the user can say. Make sure to add a list of choices because it heightens the accuracy of your command.
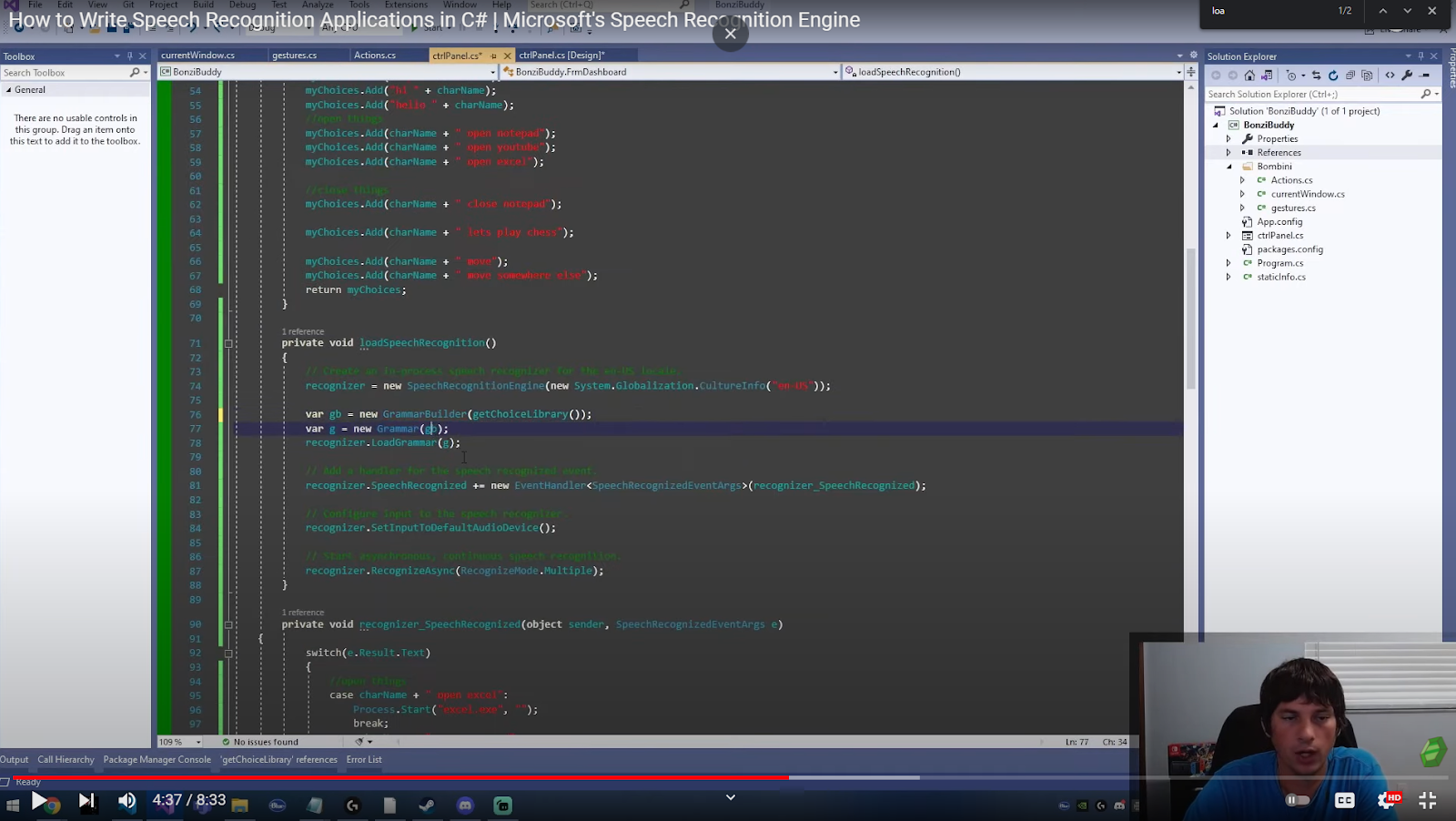
After you have built your set of choices, it will return back over here to this grammar builder. This is where you can tell the API how a sentence should look.

The next step is the speech recognized event handler.
public void recognizer_SpeechRecognized(object sender, SpeechRecognizedEventArgs e)
{
bombini.processSpeech(e.Result.Text);
}This action is what your recognition engine hears (something that matches with one of the choices), it will call whatever function you have built. I have it calling a function with a few different commands that it can run.
public void processSpeech(string speechText)
{
string currWinTitle = currentWindow.GetActiveWindowTitle();
switch (speechText)
{
//open things
case charName + " open excel":
myActions.startProcess("excel.exe", "");
myActions.animate(gestures.Write);
break;
case charName + " open notepad":
myActions.startProcess("notepad.exe", "");
myActions.animate(gestures.Write);
break;
case charName + " open youtube":
myActions.startProcess("chrome.exe", "http://youtube.com");
myActions.animate(gestures.Search);
break;
case charName + " open davinci":
myActions.startProcess("G:\\DaVinci Resolve\\Resolve.exe", "");
myActions.animate(gestures.Search);
break;
}
}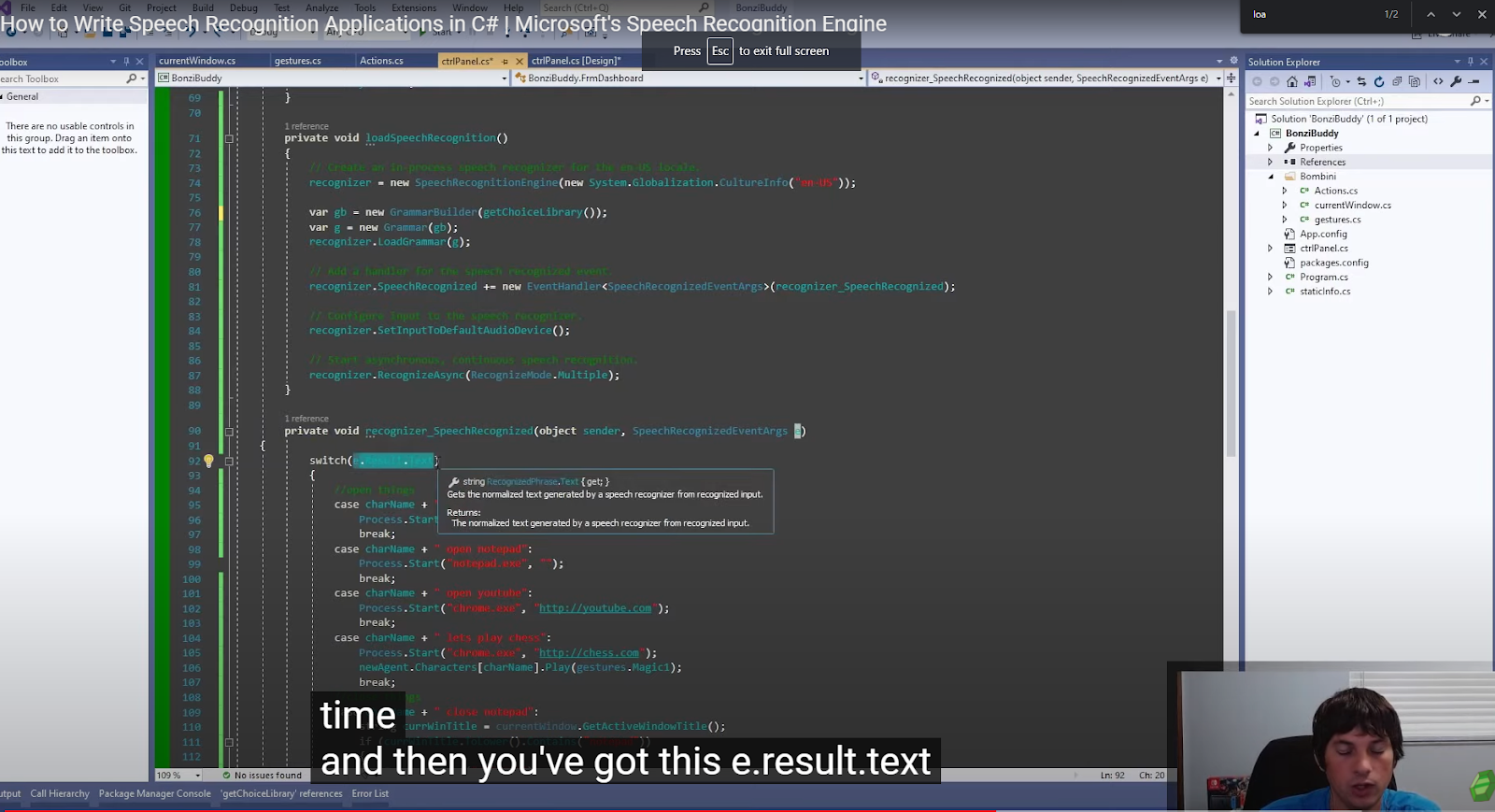
You could also take a look at “e.result.text” which is going to be the result that the recognizer will generate.
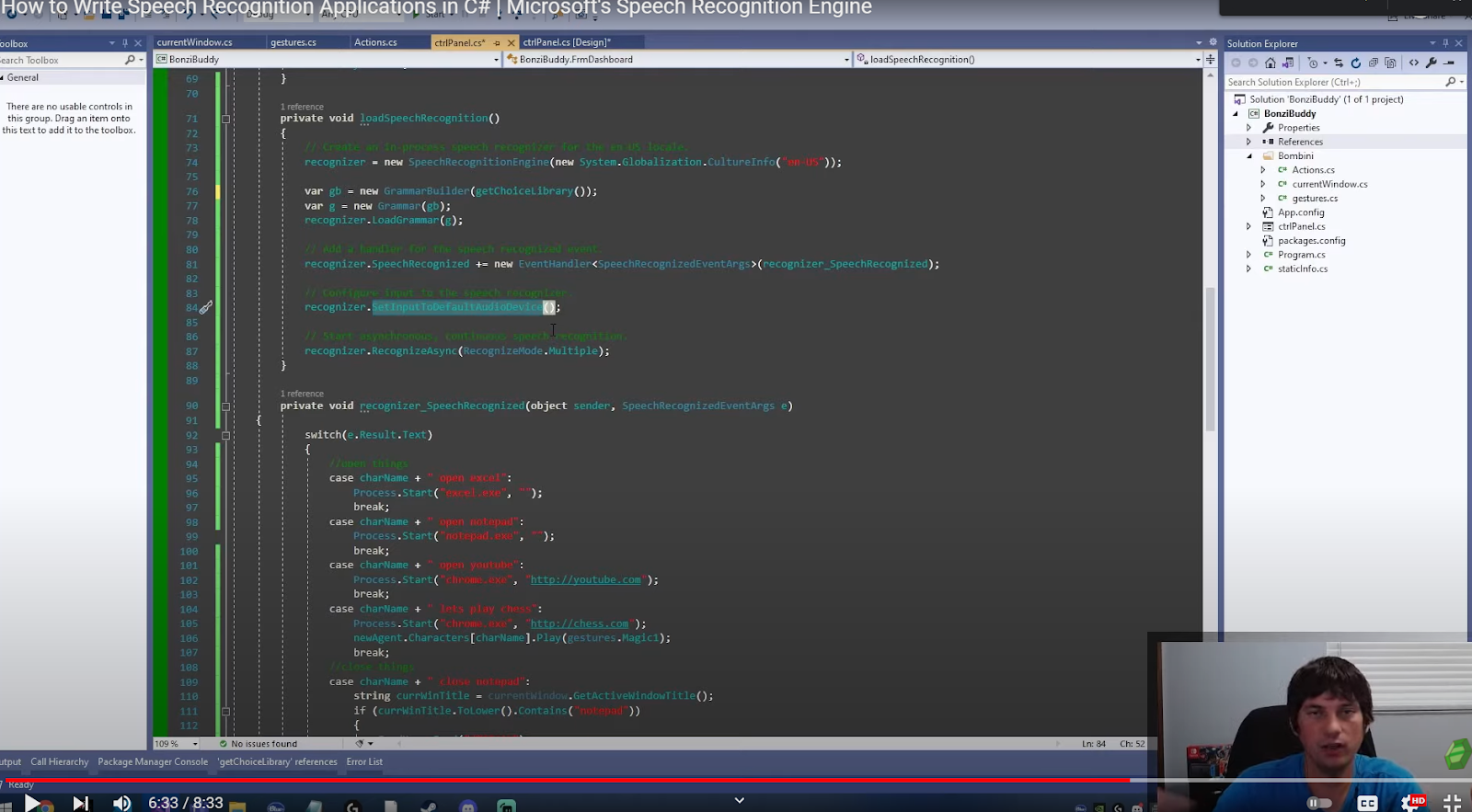
After setting up the event handler is set to listen to input from the default audio device. This determines if it will be listening on your microphone or listening to a headset.
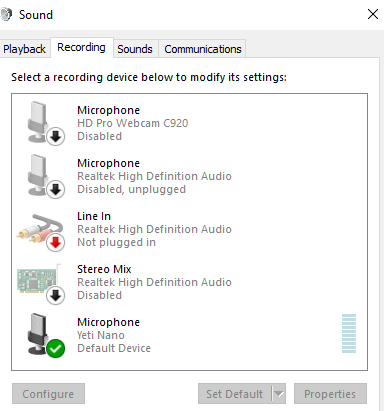
Once you have the above set up your application should be able to listen on the correct device.
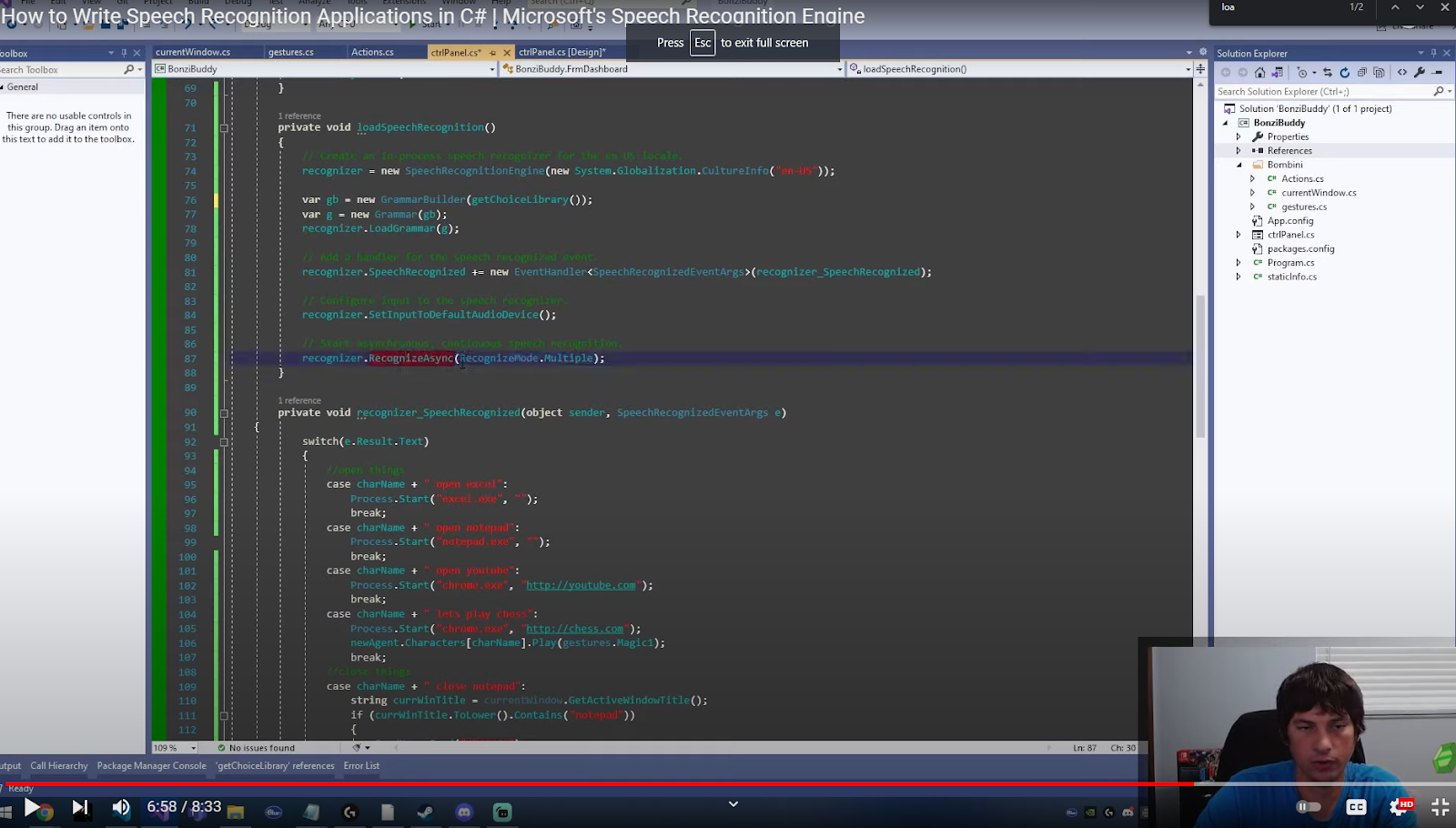
Once you have followed all of the above steps, we can start the Speech Recognition Engine asynchronously which will begin listening on another thread. Starting the Engine asynchronously makes it keep listening constantly on a second thread instead of blocking the current thread.
That is it! There are plenty of other possibilities to use the SAPI for, perhaps you could use it for innovative projects!
Thanks for reading and I’ll see you in the next one!